Динамическая карта сайта
Представим себе, что нам надо разработать сайт, содержащий научные статьи по различным областям, скажем, медицины. Статей немного - всего десять-пятнадцать штук, но необходимо обеспечить удобство посетителя при работе с сайтом, и, поскольку статьи большие, дать каждой краткое описание ее содержания - реферат, поскольку загружать все статьи посетителю вряд ли потребуется. Возникает вопрос - а как разместить на сайте эти рефераты и список статей? На одной заглавной странице? Но тогда она получится очень большая, и ее придется прокручивать, что, во-первых, потребует от посетителя лишних движений мышью или нажатий на клавиши, а, во-вторых, приведет к трудности восприятия всего обьема информации на странице. Разместить каждый реферат на своей странице (или даже на специальной странице с рефератами)? Но тогда для перехода на страницу с рефератом посетителю придется нажимать мышью ссылку, что, во-первых, требует лишних действий, а, во-вторых, и это главное, уводит посетителя с главной страницы, а он может затем туда и не вернуться и не посмотреть остальные разделы сайта. Как же быть? Как обеспечить удобство работы с насыщенной информацией главной страницей?
Очень хорошим способом было бы размещение всей информации (например, краткого содержания остальных страниц сайта) на его первой странице так, чтобы она была доступна вся сразу, но без прокрутки. Например, так, как сделано на странице http://antorlov.euro.ru/resurses.htm (рис.22.8). При заходе на нее в левой части страницы пользователь видит список статей, а справа от списка - небольшое приветствие. Как только он просто наведет, даже не нажмет, курсор мыши на какое-либо название статьи в списке, то на месте приветствия появится краткий реферат статьи. Нажав же на название, он может загрузить архив со статьей. Если посетитель пожелает прочитать статью в online-режиме, то для этого на странице предназначены кнопки справа, ведущие на страницы, содержащие тексты статей.
В результате посетителю, пришедшему на эту страничку, достаточно "пробежать" курсором по списку и, даже не переводя глаза, прочитать все рефераты, чтобы получить полное представление о содержании сайта.
Удобно? Да, действительно. Одно движение руки и чтение текста на одном и том же месте - и вся информация сайта вам известна.
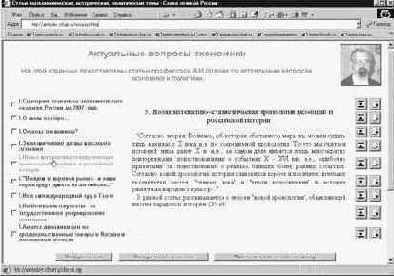
Рис.22.8. Чтобы прочитать реферат статьи, не надо даже ни на что нажимать.
Достаточно просто подвести курсор к ее названию.
Для тех же, кто привык к традиционным длинным прокручивающимся спискам статей с рефератами, предназначена специальная кнопка внизу справа под списком. При нажатии на нее на экране появится новое окно со списком статей, причем появится почти мгновенно, так как список будет не грузиться с сервера, а сгенерируется из содержимого странички.
Как же это реализовать? Использовать возможности VBScript и Dynamic HTML. Скачайте страничку с вышеуказанного адреса и посмотрите, как она устроена. Графики там мало (только фон, портрет и кнопки навигации), так что ее дизайн без графики заметно не изменится.
Для того, чтобы устройство подобной страницы было понятно, приведу краткую ее схему, в которой содержатся основные структурные элементы. Данное пояснение также демонстрирует возможности HTML и языков сценариев.
Вначале - краткое пояснение. Тэг <div> выделяет из основного текста страницы какой-либо фрагмент, которому с помощью этого тэга можно задать какие-либо свойства, назначить скрипт для выполнения. "Onmouseover" - это команда Dynamic HTML, означающая, что другая команда, заключенная в круглые скобки после нее, будет выполняться при наведении курсора мыши на тот обьект, в тэге описания которого команда "Onmouseover" присутствует. Параметр "rowspan=NN" означает слияние между собой ячеек таблицы, расположенных в одной колонке, на протяжении NN строк таблицы. "Id" - это уникальное имя какого-либо обьекта, позволяющее управлять свойствами этого обьекта с помощью скриптов. Обьяснение назначения каждой строки кода - под ней.
<html><head><title></title></head><body>
Заголовок страницы.
<div onmouseover=(document.all.txt0.innerHTML= =document.all.privet.innerHTML)>
Верхняя часть страницы. При наведении курсора на нее текст в правой части таблицы меняется на приветствие.
</div><table width="100%">
Начало самой таблицы
<tr><td> </td>
Первая колонка, соответствующая названиям статей
<td rowspan=NN>
Создание места для отображения рефератов путем слияния ячеек между собой. Число NN должно быть равно количеству статей плюс один.
<div id=txt0>
Тот самый тэг, содержимое которого будет меняться при наведении курсора на ссылки. Изначально здесь может быть короткий текст, который будет виден во время загрузки страницы - пока она полностью не загрузится.
</div>
<div style="display: none" id=privet>Приветствие</div>
Приветствие посетителю. Оно будет загружаться тогда, когда курсор находится над верхней или нижней частью таблицы, замещая собой текст предыдущего тэга. Само по себе не видно посетителю - это просто "место хранения" текста приветствия.
<SCRIPT FOR=window EVENT=onload LANGUAGE="JScript">
document.all.txt0.innerHTML=document.all.privet.innerHTML;
</SCRIPT>
Этот скрипт исполняется сразу после окончания загрузки страницы и автоматически замещает изначальный текст тэга <div id=txt0> на приветствие, без каких-либо движений курсора.
<div style="display: none">
<div id=txt1>Реферат 1</div>
...
Основное "хранилище" текстов рефератов. Каждая строка типа <div id=txtNN>Реферат NN</div> содержит текст одного реферата. Поскольку перед этой группой строк стоит тэг <div style="display: none">, то посетителю содержимое этих строк не видно - они служат лишь "источником текстов": тексты рефератов берутся отсюда по мере необходимости.
</div></td><td> </td></tr>
Правая часть первой строки таблицы. Содержит описание еще одной колонки - для того, чтобы можно было разместить в правой колонке ссылки на online-варианты статей.
<tr onmouseover=(document.all.txt0.innerHTML= =document.all.txt1.innerHTML)>
<td><a href="file1.zip">Статья 1 - загрузить</a></td>
<td><a href="stat1.htm">Прочитать</a></td></tr>
...
Основной блок сценария. Каждый такой фрагмент описывает одну строку таблицы, строка содержит название статьи, ссылку на ее архив, ссылку на online-вариант статьи, а также команду Dynamic HTML, выпол няющуюся при наведении курсора на строку и заменяющую содержимое видимого тэга <div id=txt0> содержимым соответствующего невидимого тэга <div id=txtNN>Реферат NN</div>.
Таких фрагментов должно стоять друг за другом столько, сколько рефератов и статей представлено на странице. Естественно, в каждом следующем фрагменте ссылки и параметр onmouseover должны быть другими, - document.all.txt0.innerHTML=document.all.txt2.innerHTML и т.д.
</table>
Конец таблицы
<INPUT TYPE=button id=btn1 value="Прочитать все описания">
Кнопка, запускающая скрипт, помещенный ниже. Он выводит содержимое всех тэгов <div id=txtNN>Реферат NN</div> в отдельное окно - чтобы те, что привык читать длинные страницы со списками ресурсов сайта, могли бы прочесть все рефераты в привычной обстановке.
<SCRIPT ID=clientEventHandlersVBS LANGUAGE=vbscript>
Заголовок скрипта. В нем указывается язык скрипта - VBScript.
Sub btn1_onClick()
Означает, что скрипт выполняется при клике на кнопку btn1.
Set nwnd=window.open
Эта команда открывает новое окно браузера и подготавливает его для вывода в него данных.
er="URL сайта"
Адрес сайта, на котором расположены архивы статей (с знаком "/" в конце). Подставляется в адреса для скачивания файлов в тексте открытого нового окна - чтобы можно было сохранить этот текст на жестком диске и впоследствии загрузить файлы.
nwnd.document.writeln ("<html><title>Статьи</title> <body><p>Список</p>")
Запись заголовка новой страницы.
nwnd.document.writeln (txtNN.innerHTML+"</p> <a href="+er+"fileNN.zip> Скачать </a>")...
Собственно выведение текстов рефератов в новое окно. Таких строчек должно быть столько же, сколько и рефератов. В каждой строчке должно быть указано соответствующее значение txtNN
и fileNN - для каждого реферата.
nwnd.document.writeln ("<p>Эти статьи доступны на <a href="+er+">сайте</a></p></body></html>")
Запись конца страницы.
End Sub
</SCRIPT>
Конец скрипта.
<div onmouseover=(document.all.txt0.innerHTML= =document.all.privet.innerHTML)>
Нижняя часть страницы. При наведении курсора на нее текст в правой части таблицы меняется на приветствие.
</div></body></html>
Конец страницы.
Этот текст является основой, "костяком" страницы. При разработке сайта на эту основу можно добавлять графику, текст, другие скрипты. Так, поскольку Netscape Navigator и остальные браузеры не поддерживают многие возможности Dynamic HTML, то для них не стоило бы скрывать текст рефератов - они ведь тогда не смогут его отобразить! Выход - в небольшом скрипте:
<SCRIPT language="JavaScript">
if (navigator.appName == "Microsoft Internet Explorer")
{
document.write ("<div style=\"DISPLAY\: none\">");
}
</SCRIPT>
Этот скрипт нужно расположить на месте тэга "<div style="display: none">" перед текстами рефератов, и тогда они будут скрыты от посетителя тогда и только тогда, когда посетитель использует браузер Microsoft Internet Explorer, поддерживающий Dynamic HTML в полном обьеме. Однако, поскольку в настоящее время браузер Netscape Navigator и другие используется где-то в 5-10% случаев (данные по счетчику Hotlog на весну 2002 г., рис.22.9), то лучше использовать только реализацию для Microsoft Internet Explorer, а для Netscape Navigator, Opera и других браузеров сделать отдельную страницу с автоматическим переходом на нее, вставив для этого в самое начало страницы следующий скрипт:
<SCRIPT LANGUAGE="JAVASCRIPT">
if (navigator.appName != "Microsoft Internet Explorer")
{
window.location.replace("Страница_для_NN.htm");
}
</SCRIPT>
Для Netscape Navigator можно использовать традиционную структуру страницы без использования вышеописанных возможностей.

Рис.22.9. Статистика использования браузеров